


Detección de emociones en el habla mediante Deep Learning
Investigadores de la Universidad Politécnica de Madrid trabajan en un modelo basado en redes neuronales profundas para reconocer emociones en el lenguaje hablado.
3.10.22
Detectar la agresividad en las llamadas a call-centers, monitorizar el estrés en pilotos de aviones o permitir la creación de servicios de chat en el ámbito de la psiquiatría y de la psicología son solo algunas de las aplicaciones que pueden tener los sistemas de reconocimiento de emociones mediante voz.
Si bien es un campo relativamente nuevo, investigadores de la Escuela Técnica Superior de Ingenieros Informáticos de la Universidad Politécnica de Madrid (UPM), en colaboración con el Grupo de Inteligencia Computacional de la Universidad del País Vasco (UPV/EHU), están trabajando para que, a través de técnicas de Deep Learning, sea posible crear un modelo basado en redes neuronales profundas que permita reconocer emociones en el lenguaje hablado. De este modo, “el sistema puede reaccionar de una u otra forma según cada caso, monitorizando las respuestas para orientar el diálogo o redirigirlo a un humano”, explica Javier de Lope, profesor de la UPM y miembro del proyecto.
El grupo de investigadores, perteneciente al Departamento de Inteligencia Artificial de la ETSIINF, lleva años trabajando en sistemas de reconocimiento de emociones tanto desde una vertiente clásica de Machine Learning como con la aplicación de técnicas de Deep Learning.
“El modelo que se propone en este trabajo utiliza este segundo tipo de técnicas. Nos centramos en el reconocimiento de un conjunto básico de ocho emociones primarias, siguiendo uno de los modelos de más aceptación en dominios de estudio del comportamiento, como psicología y neurología”, añade. Estas emociones se asocian con estados o situaciones de calma, felicidad, tristeza, enfado, miedo, asco y sorpresa, a las que se añade un estado neutral.
Según De Lope, “el reconocimiento de emociones mediante voz es un campo mucho menos estudiado que el de reconocimiento de voz. El objetivo no es identificar solo la palabra, sino que incorpora también la forma en que se dice, que está asociada al estado de ánimo del hablante”. Se trata de técnicas que tienen aplicación en muchos campos en los que el aspecto social es relevante, como en la robótica social -que viene a suplir o complementar carencias de tipo afectivo y relacional- o en la ayuda a la detección de estados de ansiedad o depresivos.
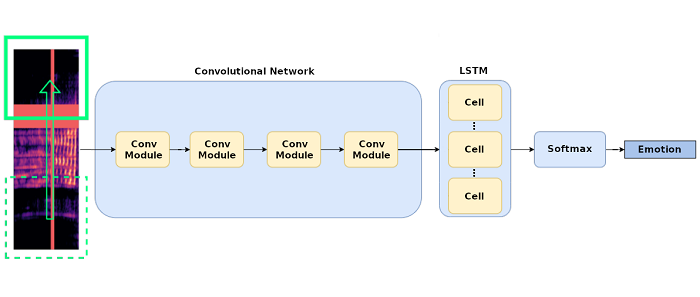
Una red neuronal profunda
Básicamente, se generan un tipo especial de espectrogramas a partir del audio, que se utilizan para alimentar la red de neuronas. El modelo de red propuesto procesa las imágenes de los espectrogramas como secuencias. Consta de un primer conjunto de capas convolucionales que extraen características de las imágenes, seguido de más capas que permiten tratar la información temporal inherente en las alocuciones. El modelo ofrece un conjunto de valores como salida, a partir de los cuales se determinan las emociones asociadas con los audios de entrada.
La investigación está enmarcada en el proyecto del Ministerio de Ciencia e Innovación de la convocatoria de proyectos “Avances en técnicas de inteligencia computacional para el proceso de sensores múltiples portables para aplicaciones biomédicas, en neurociencias y de interacción robótica” de 2020.
Una de las líneas de trabajo definidas en el proyecto propone el estudio y desarrollo de sistemas para aplicaciones biomédicas e interacción con robots. En este tipo de sistemas se utilizan datos captados con diferentes tipos de sensores como, por ejemplo, cámaras de vídeo RGB y profundidad, dispositivos de captación de sonido, sensores inerciales de captura de movimientos, dispositivos de captura de señales fisiológicas como ondas cerebrales, entre otros.
Los resultados conseguidos hasta ahora son satisfactorios. “Con el prototipo actual se ha conseguido superar el rendimiento de la mayor parte de los modelos del estado del arte, a la vez que se han reducido los requisitos computacionales para el modelo de red de neuronas”, explica el investigador. “Se siguen ensayando mejoras y optimizaciones, tanto en los modelos de Deep Learning como en el tratamiento previo de los datos generados a partir de los audios de las alocuciones que se utilizan durante el entrenamiento de las redes. Por ello, prevemos un aumento en el rendimiento en siguientes versiones”, concluye.
J. de Lope and M. Graña. A hybrid time-distributed deep neural architecture por speech emotion recognition. International Journal of Neural Systems, 32(6):2250024, 2022. https://doi.org/10.1142/S0129065722500241.